
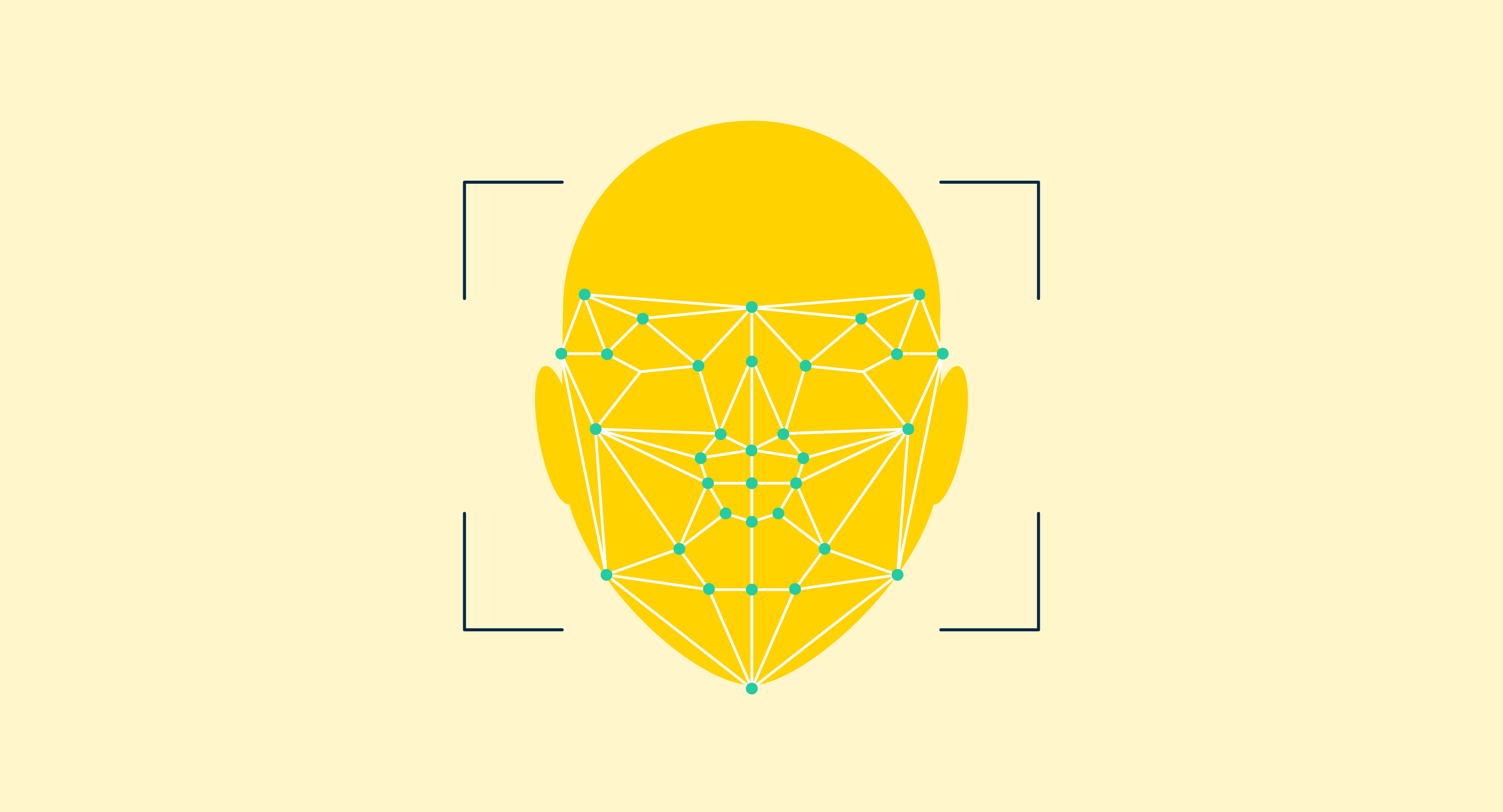
Our world is full of images, and most of the time, we humans can decipher exactly what those images are and what they mean quite easily. For computers, that’s not so simple.
However, over the past decade, advances in artificial intelligence (AI) and machine learning have significantly improved computers' ability to understand visual content.
Using complex image recognition tools, computers can now identify different elements within an image and convey that information to us. As a result, they are much better equipped to interpret and explain what an image is about.
Image recognition is a sub-category of computer vision, a broader field where visuals are identified and processed in an attempt to make them as similar to human vision and understanding as possible. As AI becomes more sophisticated, so does image recognition software and its ability to understand visual content.
What is image recognition?
Image recognition is a process where machines identify objects or features, such as people or animals, within a visual image. Through a complex process of analyzing pixels and their regularities, patterns, colors, and shapes, computers can determine what the image depicts and classify it similarly to how a human would interpret it.
As a multi-step process, image recognition involves gathering initial data about an image, followed by processing it through the machine. The data is then analyzed against the real-world examples the machine has been trained using. These training data sets are critical in building a foundation from which image recognition software can learn and make the recognition of future images more accurate.
Image recognition example
Some examples of image recognition are Facebook's auto-tagging feature, the Google Lens app that translates images or search elements, eBay's image search, and automated image and video organization in Google Photos. By analyzing image parameters, image recognition can help navigate obstacles and automate tasks that need human supervision.
Another simple example of image recognition is optical character recognition (OCR) software, which identifies printed text and converts non-editable files into formattable documents. Once the OCR scanner has determined the characters in the image, it converts them and stores them in a text file.
It goes without saying that all image recognition techniques can be applied to video feeds. Because, fundamentally, a video consists of a group of pictures that are shown quickly. So, the technique of image recognition can be applied to videos.
Want to learn more about Image Recognition Software? Explore Image Recognition products.
Image recognition vs. object detection
Image recognition involves identifying and categorizing the objects found within an image or video, using learned patterns and features to accurately determine the content. The goal is for the machine to identify what’s happening in the image like human perception.
Object detection, on the other hand, has a more focused goal of identifying particular objects within an image.
In other words, image recognition broadly interprets the overall content of an image, whereas object detection is tasked with identifying and classifying specific parts of the image as defined by the user.
Both processes use machine learning algorithms to learn, process, and classify the various elements within an image. However, their goal and outcome slightly differ—object detection is more specific with a narrower scope of work.
Image recognition vs. computer vision
Image recognition is a sub-category of computer vision. Many use these two terms interchangeably.
-png.png)
Computer vision is a broad field that includes different tools and strategies that is directed to infuse visual capabilities within machines and computing systems. These techniques include object tracking, image synthesis, image segmentation, scene reconstruction, object detection, and image processing. The computer vision technique powers several innovations like medical imaging, anatomical organ study, self-assist cars, robotic process automation, and industrial automation. The prime goal is to replicate human vision capabilities within computing systems so that they can complete more than one task at a time by acknowledging its visual state and appearance.
Image recognition is a sub-category within computer vision technology that focuses on detecting, categorizing, and restructuring image elements within digital static photographs, videos, and real-world scenarios. This software is pre-trained on image sets with similar features as that of the test set. The image recognition algorithm analyzes the location of objects, extracts features submits them to a pooling layer, and finally feeds the features to a support vector machine (SVM) to do the final classification. Common applications include facial recognition, biometric authentication, product identification, and content moderation.
Types of image recognition
Image recognition is typically broken down into three categories based on how the machine has been trained:
- Supervised learning. When data is labeled and the categories for image elements are known in advance, supervised learning is the best approach to use. It can distinguish different categories, for instance “not a cat” and “a cat”, and recognize these parts of the image.
- Unsupervised learning. When categories are unknown and images are fed into the machine, unsupervised learning recognizes patterns in the data. Analysis of the image is based on attributes and characteristics rather than pre-programmed categories or objects.
- Self-supervised learning. When there is some labeled data, but the machine is still learning how to function with less specific information, self-supervised learning can be a good approach to utilize. It is a subset of unsupervised learning, where labels are created during the analysis process. More oversight is required in this critical training step, as it determines how well the machine can recognize future images.
Within each of these categories, various types of applications can be used for more extensive and specific image recognition. These include:
- Facial recognition. This specialized type of object recognition trains machines to identify and process individual facial features. Applications range from security and surveillance to law enforcement. For example, airport security and border control now often use facial recognition to compare the features of a human standing in front of the camera to the identity document to verify their identity.
- Scene recognition. Landscapes and buildings can also be identified by image recognition software. This can be used in various ways, such as self-driving vehicles, mapping systems, or gaming software like augmented and virtual reality headsets.
- Gesture recognition. While identifying static images is challenging for computers, recognizing and assessing moving gestures, particularly those of humans, can be even more complex. Image recognition tools can be programmed to read and understand hand movements, facial expressions, and more.
- Optical character recognition (OCR). Fixed characters like letters and numbers are easier for computers to decipher, particularly when the machine has been trained to pick up these visuals and has pre-assigned categories for organizing them. Handwritten documents may need to be scanned and converted into digital text. This technique is one of the easiest and quickest ways to digitize written information.
How does image recognition work?
For a computer to recognize images and patterns, it employs a process known as deep learning. This is a form of machine learning where deep neural networks replicate the complex decision-making powers of the human brain in an artificial environment.
These deep neural networks are made of three or more layers, often hundreds or thousands, that train the image recognition software model for real-world applications. Much like our brains contain numerous interconnected nodes to pass information throughout our bodies, these computer networks operate in a comparable manner.
These nodes in the network identify what the computer is seeing, weigh different options, and then provide a concluding outcome on what the image shows. Training these nodes is crucial to the machine to learn and improve its accuracy over time.
The machine must be trained using a large dataset, which helps it learn and identify the necessary features of different objects. Once trained, the image recognition process typically follows these six steps:
- Data collection. Data is fed into the machine, usually in a supervised learning setting with labeled images.
- Pre-processing. Before training begins, images are adjusted to remove any distortions or interferences. This may involve cropping, brightening, or otherwise adjusting the images to make them as useful as possible for the machine.
- Feature extraction. Isolating the parts of the image that need to be categorized is an essential step in training. This helps the machine distinguish between different parts of the visual.
- Model training. Using the labeled datasets, the neural network of the machine is trained repeatedly until patterns and features are recognized with a high level of accuracy. Tagging and segmentation occur during this phase, giving the model more information to understand the image.
- Model testing. Different datasets will be used to continue training and testing the algorithm until it’s ready for deployment. These datasets will likely become more complex over time, moving from labeled to unlabeled datasets to help the machine learn and become more accurate.
- Deployment and re-testing. When the model has been sufficiently tested and validated, it can be deployed for wider use.
For example, the machine could be fed an image of two dogs playing in a backyard. The image recognition software would start identifying the elements of the image with classification, breaking out the dogs from the background. From there, they could go back to tag the individual dogs as “dog” and other elements in the image, such as “tree,” “ball,” or “fence.”
Industries benefiting from image recognition
The business applications of image recognition are becoming more extensive as AI and machine learning reach unprecedented levels of sophistication and accuracy. For tasks that could be automated or require a significant level of human effort, image recognition can significantly reduce both time and costs.
Some of the industries that are benefiting from this technology include:
- Retail. Image recognition in the retail industry is one of the best ways to improve the customer experience when shopping in-store. For example, it can pair outfits with a specific customer based on their current style. Security systems can also use image recognition to identify potential shoplifters or other security threats.
- Healthcare. Radiologists can use image recognition to quickly and easily identify problems in MRIs and other medical imaging, leading to faster and more effective treatment for patients.
- Agriculture. Pests and diseases can be disastrous for the farming community. With image recognition software, farmers can analyze the visual makeup of crops, allowing them to take corrective steps before problems are irreversible.
- Finance. Human error in accounting can be incredibly costly, but numerous tasks in the finance industry can be automated to save time and money. Invoice processing, expense management, and validating financial transactions are all examples of how image recognition can help. For example, small businesses can quickly scan a paper receipt on their phone and upload it to their accounting software. Image recognition will pull the information in the picture to automatically add this expense data to their records.
- Manufacturing. Defects in products can be costly mistakes for the manufacturing industry. Image recognition can find these errors or any deviation from the typical quality standard. For instance, in the pharmaceutical production field, image recognition can easily spot a missing pill from a packet before the manufacturing process is complete and the medication is packaged for sale in an incorrect quantity.
Tasks of image recognition software
Image recognition software is powered on deep learning, more precisely, artificial neural networks.
Before we discuss the detailed workings of image recognition software, let's examine the five common image recognition tasks: detection, classification, tagging, heuristics, and segmentation.
Detection
The process of locating an object in an image is called detection. Once the object is found, a bounding box is put around it.
For example, consider a picture of a park with dogs, cats, and trees in the background. Detection can involve locating trees in the image, a dog sitting on the grass, or a cat lying down.
Once the object is detected, a bounding box is placed around it. Of course, objects can come in all shapes and sizes. Depending on the complexity of the object, techniques like polygon, semantic, and key point annotation are used for detection.
Classification
It's the process of determining the class or category of an image. An image can only have a single class. In the previous example, if there's a puppy in the background, it can be classified as 'dogs' or simply as dog images. If there are dogs of different breeds or colors, they can also be classified as "dogs".
Tagging
Tagging is similar to classification but aims for better accuracy. It tries to identify multiple objects in an image. Therefore, an image can have one or more tags. For example, an image of a park can have tags like "dogs," "cats," "humans," and "trees."
Heuristic
The algorithm predicts a "heuristic" for every element within an image, which is a projective score of an element belonging to a specific image category. The heuristic is an estimated measure, usually measured via a distance metric like Euclidean or Minkowski metric. The heuristic is then compared with a "tensor" value, which is calculated by cross multiplication of data properties into a number of grids the image is divided into. The heuristic value sets a predetermined goal for the image recognition algorithm to achieve.
Segmentation
Image segmentation is a detection task that attempts to locate objects in an image to the nearest pixel. It's helpful in situations where precision is critical. Image segmentation is widely used in medical imaging to detect and label image pixels.
Processing an entire image is not always a good idea, as it can contain unnecessary information. The image is segmented into sub-parts, and each part's pixel properties are calculated to understand its relation to the overall image. Other factors are also taken into consideration, like image illumination, color, gradient, and facial vector representations.
For instance, if you're trying to detect cars in a parking lot and segment them, billboards or signs might not be of much use. This is where partitioning the image into various segments becomes critical. Similar pixels in an image are segmented together and give you a granular understanding of the objects in the image.
Benefits of image recognition
For both businesses and consumers, image recognition software has several significant benefits.
Protects people from online crime
These days, our faces are all over the internet, along with seemingly endless personal information. With image recognition tools, image searches can be completed to check for unauthorized usage of your information for fraud.
For visual artists, this is also a good way to identify if anyone is stealing or misusing your artwork.
Processes data quickly
AI image recognition can process large datasets exponentially faster than a human could. This not only frees up your team to do other tasks that are more business-critical but also completes the work in a much faster time.
Scalable solutions for any visual project
AI systems have a diverse range of applications, which means they can be used for almost anything. That makes image recognition software one of the most adaptable and flexible options for any kind of project, no matter the size.
Best image recognition software
With its range of capabilities, the right image recognition software depends on your specific need and the desired outcomes. Most tools can handle a variety of data inputs, including the top free image recognition software. But for more complex projects, paid-for software is often the best choice.
To be included in the image recognition software category, platforms must:
- Provide a deep learning algorithm specifically for image recognition
- Connect with image data pools to learn a specific solution or function
- Consume the image data as an input and provide an outputted solution
- Integrate image recognition capabilities into other applications, processes, or services
* Below are the top five leading image recognition software solutions from G2’s Spring 2024 Grid Report. Some reviews may be edited for clarity.
1. Google Cloud Vision API
Google Cloud Vision API allows developers to easily leverage the power of AI and machine learning to recognize and assess images with industry-leading prediction accuracy. The tools allow you to upload images directly, with the Vision API acting as an object localizer to detect objects and labels within the image itself.
What users like best:
“We are using the API in a project where we have to know food's nutritional value so we get the food name by image recognition and then calculate its nutritions as per food contents. It is very easy to integrate it with our application and the api response time is also very fast.”
- Google Cloud Vision API Review, Badal O.
What users dislike:
“Depending on usage, costs associated with using Google Cloud Vision API can accumulate. Users should carefully review the pricing model and estimate potential expenses for their specific use cases.”
- Google Cloud Vision API Review, Piyush D.
2. Syte
Powered by AI, Syte is the world’s first product discovery platform. With camera search, personalization, and smart eCommerce tools, businesses can help customers discover and purchase products with a hyper-personalized experience on their online store.
What users like best:
“The shop similar tool has been a great tool since we've implemented it on our sites. The Syte tool has been instrumental in product discovery and helping customers find visually similar products when they can't find their size.”
- Syte Review, Emely C.
What users dislike:
“The backend merch platform is not the most intuitive as other platforms. The “complete the look” doesn't showcase the exact products as part of the look, only lookalikes.”
- Syte Review, Cristina F.
3. Carifai
Carifai is a full-stack AI platform for developers and teams to collaborate on audio and visual AI productions. The custom language learning models are open source, with frequent updates, and can serve multi-modal uses across a range of projects and industries.
What users like best:
“Easy to navigate and a very wide selection of user built models to start playing with and learning. Feels like github but with AI. Easy for a beginner like me to find what I'm looking for. Quick and easy signup and you can get started right away without any annoying demo call or sales pitch first.”
- Clarifai Review, Tate T.
What users dislike:
“It could be good to have the training library beefed up even further as the use cases and models are relatively new. It would be good to have walkthroughs of how to implement models end-to-end for different model types.”
- Clarifai Review, Sam G.
4. Gesture Recognition Toolkit
Gesture Recognition Toolkit is an open-source and cross-platform tool suite that allows developers the freedom and flexibility to design and build real-time gesture recognition software. Largely used in gaming development and virtual reality, users of the toolkit can create from scratch or work with other community members to leverage open-source applications to build their language learning models.
What users like best:
“I like how it is designed to work with real time sensor data and at the same time the traditional offline machine learning task. I like that it has a double precision float and can easily be changed to single precision, making it a very flexible tool.”
- Gesture Review, Diana Grace Q.
What users dislike:
"It has an occasional lag and a less smooth implementation process. Customer support response time could be faster.
- Gesture Review, Civic V.
5. SuperAnnotate
SuperAnnotate is a leading platform for building, training, testing, and deploying AI models with high-quality training data. Advanced annotation and image recognition tools allow users to build successful machine-learning pipelines and manage automation workloads.
What users like best:
“SuperAnnotate has an intuitive interface. It was straightforward to get familiar with the different functions and tools that the platform provides. It is easy to navigate amongst the thousands of images in our dataset - both in annotation mode and outside. This has been very useful in situations where I have had to find specific images to make some changes to the dataset. In addition the label overview feature is useful for detecting and correcting any inconsistencies in our annotations.”
- SuperAnnotate Review, Camilla M.
What users dislike:
“The platform can provide more filter options for manager accounts and additional functions for annotators to fix unintentionally sent tasks.”
- SuperAnnotate Review, Hoang D.

It's almost unrecognizable...but not quite!
Visual images and videos play a critical role in our lives, both personally and in the workplace. Having technology at our fingertips that can detect and assess these visuals in almost the same way as a human brain is a significant step in artificial intelligence, with endless possibilities for how these tools can benefit our everyday lives.
Learn more about AI applications so you can automate more tasks and everyday functions in your business.
Amal Joby
Amal is a Research Analyst at G2 researching the cybersecurity, blockchain, and machine learning space. He's fascinated by the human mind and hopes to decipher it in its entirety one day. In his free time, you can find him reading books, obsessing over sci-fi movies, or fighting the urge to have a slice of pizza.

