
Raw data makes no sense. Making it business ready involves a lot of time, resources, and of course, coffee.
Data scientists manage data in three ways: management, analysis, and visualization. Machine learning (ML) models are a combination of all of them. It checks on your data, tests its usability, and converts it into your expectations.
The need for machine learning models is blowing up in commercial and non-commercial industries. Data optimization with artificial intelligence and machine learning operationalization software has become the crux of all production operations. Where most businesses are looking to sack clients, machine learning models are bringing about a huge data-driven revolution.
A machine learning model is a graphical representation of real-world data. It’s programmed in an integrated data environment and works on real-life business cases. It trains on old data and works on fresh data. It takes time to program, test, and validate machine learning models before leveraging them to make business decisions.
Machine learning and artificial intelligence (AI) stints go back to the 20th century. The idea of the “supercomputer generation” or “fifth generation of computers” created a growth spurt of technology in a vacuum computer world.
The early conception of machine learning began in 1943 when logician Walter Pitts and neuroscientist Warren McCulloch built a mathematical model of a neural network. They aimed to replicate the working of the human brain. A decade later, computer scientist Arthur Samuel coined “machine learning” and described it as “ a computer’s ability to learn without being explicitly programmed.”
The concept was first born in 1945, when Joseph Weizenbaum discovered natural language processing (NLP) as an offshoot of artificial intelligence. Slowly. newer machine-learning concepts replaced the older ones. Slowly, with the evolution of big data, machine learning incubated a higher form of computer intelligence. This intelligence was more accurate, focused, and lightweight than earlier inventions.
Although machine learning models weren't 100% accurate in terms of output, they give a steady prediction. The prediction accuracy also depended on the kind of training data it worked on. These models learned the similarities between external and internal data to draw projections.
Machine learning models are used to draw insights from already existing data. It is used to automate business operations to drive growth. However, certain problems might not need a data-driven approach. Such problems don't require machine learning and can be tackled with standard mathematical calculations. Some eligible scenarios where machine learning is a must is:
Did you know? You can evaluate a machine learning model with cross-validation. It involves training the model on input data and testing it on complimentary test data. It prevents overfitting of the model and helps draw similar patterns for future predictions.
There are three major types of machine learning models. While all machine learning modeling techniques work on a common purpose, their way of approaching a data problem differs.
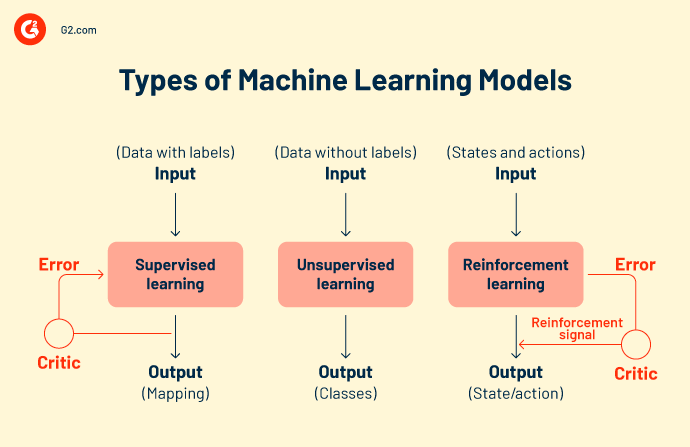
As these models get exposed to more data samples and inputs, it gets better at learning and calculating predicted values. The models develop intelligence with time, constant learning, and experimentation.
In supervised learning, the machine learning model is taught with predefined inputs.
The model is equipped with both input and output signals. It just needs to figure out how to arrive at an output value. The machine learning model goes through the training process, maps features, and classifies them for incoming data.
Next, it tries to catch the nearest output signal as the input value gets stored. It uses boolean expressions to calculate data values. Data scientists or ML engineers train this model with a known dataset that comprises input and output. The algorithm needs to devise an interpretation strategy on its own. If a discrepancy occurs, the human user corrects it.
The process iterates till the model receives a high degree of accuracy. Examples of supervised learning include optical character recognition, pattern recognition, and voice recognition.
Unsupervised machine learning models identify hidden patterns in data to form relationships and draw conclusions. They process input datasets by comparing them against stored information. The accuracy rate of an unsupervised algorithm only grows when it works with as much fresh data as necessary.
Example: If unsupervised machine learning runs on an image of dogs and cats, it can’t tell if the picture is a dog or a cat because their physical attributes are too similar. It won’t be able to distinguish their separate features and will return a confusing output. The classification accuracy of the model increases when it runs on multiple images.
In reinforcement learning, the algorithm behaves like an intelligent agent that learns from every unsuccessful operation. The model adapts from incorrect outputs and strives to achieve the end goal. A feedback cycle rewards the model with procured intelligence when the output is correct. But when it’s incorrect, the model learns from its mistakes.
Each of these three types of machine learning models encompasses different techniques of model creation. Let's look at the most popular ones for now.
Classification, regression, and forecasting are data analysis techniques under supervised learning.
In classification tasks, ml modeling helps assign a category to data. They must draw conclusions from observed values to classify the output. For example, when classifying patient data as “new” or “old,” an ML model should look at existing registration dates to bucket the data.
The two types of classification algorithms are binary classification and multi-class classification. Binary classifiers return the output as yes/no or true/ false. They’re only responsible for checking whether a particular data class is present or not. On the other hand, if the problem has more than two possible outcomes, it’s called a multi-classification problem.
Regression is a machine learning method focused on one dependent variable for a series of output variables. The analysis of a regression algorithm makes predictions accurate and useful. It goes through a series of steps like data directionality, analysis of variance (ANOVA), hypothesis testing, and final model creation.
Machine learning models solve seven kinds of regression problems:

Y = mx+c+e
Y = predicted value
m = dependent variable
c = constant
The aim of linear regression is to find a good fit model that shows accurate predictions on test data.

This formula is denoted by the logit function, which measures the relationship between the target variable and independent variables.
Logit (p) = In(p/(1-p)) = b0+b1X2+b2X2……+bkXk
p = probability of a feature

Forecasting is a trend-based methodology that predicts the future with present-day or past data. It’s mainly used to extrapolate current business trends and market potential for companies making investment decisions. The most prominent method of forecasting is time series forecasting.
Time series forecasting is a data analysis method to make scientific predictions. It involves building models through historical data analysis over a specific time frame. Examples include weather forecasting, natural disaster forecasting, and epidemic forecasting. The accuracy of time-series forecasting is certain as it works on evidentiary data.
Examples are XGboost, exponential smoothing, autoregressive, and DeepAR.
Data scientists or ML engineers use unsupervised learning to build self-assist machine learning models. These models learn and improve on their own, without external data tether.
Clustering is the process of dividing input data into baskets of similar categories for further classification. Two effective methods of clustering are best suited for your data.
Random sampling is a statistical interpretation method that creates random samples of data. It baskets data into different clusters based on their nature, type and behaviour. It is used to calculate census, product supply and demand, and revenue collection in particular areas. Random sampling is similar to clustering but isn’t reliable in terms of accuracy.
Associate rule learning imposes certain rules for data classification. It creates interesting relationships and patterns between data and maps co-dependencies in a way that generates maximum profit. Examples are data mining or market basket analysis.
This technique eliminates dirty data, outliers, and uneven values, making the input dataset cleaner and crisper. Examples include principal component analysis or K-means clustering.
Deep learning requires large datasets and high graphical computational power (GPU) to predict the class of input variables. It involves neural networks that are made up of activation function and trigger nodes. The network accepts input through input layer, triggers decision nodes through activation function and processes output. The most significant models are:
To error is human. To error is also machines.
Reinforcement learning appoints a smart agent to work on data. These intelligent actions take action in a machine-learning environment to predict correct outcomes. If reinforcement learning predicts a correct output, it gets a cumulative award. It is one of the three basic ML paradigms of reinforcement learning.

Some popular reinforcement models include.
Q-learning is a popular reinforcement algorithm that helps AI agents make wise decisions. With this algorithm, you can compute q-value, take the required action, and maximize reward points.
State-action-reward-state-action (SARSA) is an on-policy algorithm that calculates the q-value for each state-action pair. For each specific state of the input, there is one designated output and one designated reward in case the output is accurate. Each letter in SARSA represents a row.
A deep Q. network, or deep Q. neural network, is an artificial neural network that has many computational layers. It processes output based on input, weights, and added bias.
Different machine learning models have different utilities and accomplish different sets of goals. You must choose which model will work best for you in the long run.
No matter the approach, the end result is always a model that acts upon data. Deep learning. Machine learning or algorithm is the second name of data management, as your data scientist might attest.
-png.png?width=600&height=333&name=Copy%20of%20X%20vs%20Y%20vs%20Z%20(9)-png.png)
Algorithms are a set of programming expressions that are self-explanatory. They execute a thread of commands on the input data. A machine learning algorithm is coded in open-source tools like Python, Java, or TensorFlow. You need to call a specific package from the package library and install its directories. After that, you can load your datasets, set the axis, and create models. Some packages are Scikit learn, NumPy, or Matplotlib.
The machine learning model is the final creation of a data algorithm. The models are categorized as skewed, normal, or a good fit. The properties of data and the accuracy of the algorithm are the main contributors to a machine-learning model. The model is deployed on test data and extended into an organization's workflow applications.
The deep learning model is one step ahead of the machine learning models. These models are trained to extract and store individual features from data and then use them to make accurate predictions. However, these computing systems need large datasets, image sets, and high graphical computational power (GPU). Examples are the convolutional neural network (CNN), recurrent convolutional neural network (R-CNN), and “you only look once” (YOLO).
Grasping the technicalities of data can be very tricky. And a lot of trickiness lies in how you choose your ML models.
Tip: You can use machine learning as a service (MLaaS) to outsource machine learning processes for your business workflows. This service is a collection of different cloud-based software that deploy machine learning tools to provide predictive analytics solutions to your ML teams for various business use cases.
To find the best model, take a long look at your existing IT infrastructure. Your current on-premise network will pave the way for future hardware and software compatibility. Factor in your budget, bandwidth, local area network (LAN), data scientists' bandwidth, and other facility maintenance policies to make your machine-learning models work in tandem.
A safe way is to start small. Build a proof-of-concept framework and gauge your AI maturity. Use existing data attributes, volume, features, and complexity to build an intermediate machine-learning model. Validate and test it for small projects and business use cases. When your model sets in with data, deploy it at a bigger scale.
As you progress, count on more team bandwidth, budget, and data scientist's efforts. A lot of effort goes into managing, training, and diagnosing ML models, which can eat into your business resources.
Did you know? The global artificial intelligence market was valued at $93.5 billion in 2021 and is projected to expand at a compound annual growth rate of 38.1% from 2022 to 2030.
Source: Grand View Research
While the machine learning model represents your data mathematically, it doesn’t come into action on its own.
Machine learning is the present, but it also lights the way to a digital future. Gather a copious amount of research, study existing processes, and decide what option will put you at the forefront of the software marketplace.
learn how you can choose the correct data science and machine learning model for your business.
.png?width=50&height=50&name=Copy%20of%20G2%20Image%20(1).png)
 Excel your way into data science!
Excel your way into data science!
Automate and systemize your existing data workflows with artificial intelligence and machine learning operationalization software

Human's ability to speak and write flawlessly is an outcome of evolution. As AI progresses,...
by Shreya Mattoo
In the language industry, transformer models are driving innovation forward.
by Shreya Mattoo

If Beethoven were alive to hear his 10th symphony composed by artificial intelligence, he...
by Shreya Mattoo


.png?width=768&height=168&name=INFUSE%20Case%20Study%20Graphics%20(1).png)


